
La langue
- Détails
- Catégorie parente: La théorie des voix ou sémantique des relations
Lien avec Sémantique Générale
On peut mettre également en relation le chapitre X de TAL « Voix et prédication » et le chapitre VIII de Sémantique Générale « L’événement » ou B. Pottier, s’inspirant des représentations catastrophiques de René Thom, présentent les cinq aires événementielles :
L’aire existentielle
Une entité existe dans l’espace et dans le temps.
L’aire a
Une propriété peut lui être affectée (« Jean/être grand »). Une activité peut émaner d’elle (« Jean/marcher).
L’aire l
L’entité peut également entrer en relation avec le monde objectif, c’est la localisation (« Jean est dans le jardin »).
L’aire b
L’entité peut faire montre d’activité. Les activités issues de la base sont regroupées dans l’aire de l’activité m.
L’aire m
Si l’entité entre en relation avec le monde subjectif («Jean regarde la télévision »), c’est le domaine de la cognitivité (sensations, intellection, modalisation).
La rosace des possibles positionnels
D’où cinq aires événementielles données par le schéma suivant :

Le quart nord-ouest est endocentrique (les deux flèches vont dans le même sens). C'est le domaine des PROPRIÉTÉS "α".
Le quart Sud-Est est exocentrique. Il recouvre les ACTIVITÉS "β".
Le quart Nord-Est est mixte, et établit les relations de LOCALISATION "γ".
Le quart Sud-Ouest est mixte, et établit les relations de COGNITIVITÉ "μ".
Ce support sémantique a selon B. Pottier une valeur universelle. Il se situe au niveau noémique ou conceptuel, au-delà de toute langue naturelle. Au-dessous, ce sont les spécificités des LN qui apparaissent et en particulier les voix qui semblent propres à chaque langue ou à chaque famille de langues.
Deux grandes caractéristiques sont à souligner.
D’abord, l’affinité de cette représentation avec les voix qui relèvent du niveau linguistique est évidente, même si le découpage ne correspond pas exactement. L’aire a comprend les lexèmes de la voix descriptive 1 et 3, ainsi que l’équatif. L’aire l recouvre les situatifs spatiaux, temporel et notionnel. L’aire m correspond à la voix subjective. L’aire b enfin correspond à la voix descriptive 2 et à tous les cas de causatif.
Ensuite, les limites entre ces grandes classes sont des limites floues. Dans une situation concrète de communication, chaque aire peut interférer avec une autre, b avec l (« untel porte la lampe sur la table »), b avec a (« le peintre blanchit le mur »), avec $ ou avec m (« untel me fait penser à ...). En cela la représentation en rosace des possibles est particulièrement appropriée.
Enfin, la correspondance entre aires événementielles, qui relèvent du niveau conceptuel, et voix qui relèvent du niveau linguistique, montre le caractère contingent des représentations linguistiques.
Prenons un premier exemple. « J’ai faim » et « je suis affamé » relève de l’aire a, le premier se rattachant à la voix descriptive DES3, tandis que le second à la voix descriptive DES1. Il s’agit d’un pur hasard de la langue, car en anglais « j’ai faim » se dit « I am hungry » qui serait de la voix DES1. De même « il mesure 200 mètres » ou « il fait 200 mètres de long » (DES2) se dit en anglais « It is 200 meter long » (DES1), etc.
Second exemple : l’affinité entre le situatif notionnel et l’adjectif qui relève de la voix DES1. « je suis en colère » est un situatif notionnel du seul fait que la langue française ne possède pas d’adjectif pour exprimer l’état de colère momentané, alors qu’elle en possède deux pour exprimer la propension permanente à se mettre en colère : « coléreux » et « colérique ». En espagnol, la distinction entre l’état momentané et l’état naturel et permanent ne sera pas opérée au niveau de l’adjectif, mais à celui de l’auxiliaire, qui sera « estar » dans le premier cas, et « ser » dans le second.
Troisième exemple proposé par B. Pottier (les deux premiers étant de nous), qui illustre le passage de a à l au sein du français : « être embarrassé » (a) est sensiblement équivalent à « être dans l’embarras » (l). De même que « ne plus être réservé » et « sortir de sa réserve ».
Quatrième exemple de classification d’une grande finesse, mais dont l’exploitation en traitement automatique peut soulever des difficultés : la distinction entre la possession impliquée (« j’ai peur, j’ai faim, il a vingt ans, il a deux jambes »), qui exprime une relation attributive avec une forte porosité entre DES1, DES2 et DES3, relève de a et la possession non impliquée qui équivaut à un constat de savoir (« j’ai une voiture ») et qui relève de m.
Quatre conclusions doivent être tirées immédiatement de ces observations.
1) L’énonciateur dispose d’une multiplicité de choix prédicatifs pour exprimer à peu près la même chose, moyennant des nuances marginales qu’il faut le cas échéant être en mesure d’analyser. Ex. :
a = la vache est un herbivore (a et EQU-STA)
b = la vache est herbivore (a et DES1-STA)
c = la vache est mangeuse d’herbe (a et DES1-STA)
d = la vache mange de l’herbe (g et DES2-CAU)
e = la vache mange de l’herbe, dit-on (g et DES2-CAU + modalisation)
f = (regarde!), la vache mange de l’herbe (l et DES2-CAU + modalisation)
Heureusement, le langage normatif ne s’embarrasse pas de toutes ces nuances que l’on retrouve au contraire dans le langage parlé ou dans le langage littéraire, théâtrale ou poétique.
2) Si les voix peuvent se retrouver sans trop de variations d’une langue à une autre, en revanche la répartition des expressions entre les voix peut apparaître assez souvent, comme nous l’avons vu, contingente et étroitement liée à une langue particulière. Par conséquent, la théorie des voix se situe clairement au niveau linguistique et non au niveau conceptuel, à la différence de la rosace des possibles qui se situe au niveau noémique. L’important est, à partir d’une analyse linguistique, de pouvoir atteindre le niveau conceptuel. Si les traits purement linguistiques peuvent être mémorisés, on doit être en mesure de retrouver à peu près le texte initial dans la langue d’origine. Si l’on ne retient que les traits de niveau conceptuel, on doit en principe disposer d’un champ de solutions parasynonymiques plus étendu.
3) La détermination de la voix dépend d’éléments syntaxiques et sémantiques variés au sein de l’énoncé. Pour l’existentiel, il s’agira de la présence d’un présentateur tel que « c’est », « il y a », « il était une fois », etc., pour le descriptif cet élément sera l’adjectif combiné avec l’auxiliaire être, un substantif spécifique combiné avec l’auxiliaire avoir...
4) Dans la détermination de la voix d’un énoncé, l’analyse sémique va jouer un rôle prépondérant.
En effet, s’agissant des verbes, la présente de sèmes d’identification de la voix permettra de les classer aisément et d’établir la voix caractéristique de l’énoncé. Le verbe « insérer » comporte un sème générique inhérent S qui le positionne comme situatif et que son complément indirect permettra de situer dans le domaine sémantique spatial, temporel ou notionnel. Plus subtilement, la distinction que l’on doit opérer entre la possession impliquée et la possession non impliquée trouve sa solution au plan sémique. Dans « il a peur », la peur résultant d’une activité psychique du sujet en réaction à son environnement, l’emploi du mot « peur » dans le prédicat devrait impliquer la voix subjective. Or, dans TAL, « il a peur » est classé DES3, en tant qu’exprimant une sensation, ce qui n’empêche pas B. Pottier de considérer le domaine des sens, de la perception comme un des trois domaines sémantiques de la voix subjective. Nous avons du mal à ne pas trouver une incohérence dans cette classification, d’autant que la possession non impliquée (« j’ai une voiture ») est classée DES3 dans TAL, alors qu’elle constitue le point d’entrée de l’aire événementielle m de la cognitivité, dans la mesure où elle exprime un savoir relationnel, un « constat de savoir ». Nous serions tentés de proposer d’en rester, s’agissant de la possession externe, à l’interprétation de TAL, et donc de mettre ce cas en DES3, mais par contre de reclasser la possession interne dans la voix subjective et dans l’aire m lorsqu’elle exprime une activité psychique, ce qui est le cas des expressions telles que « avoir peur », « avoir faim », « avoir chaud », etc. Lorsque la possession interne (partie du corps, parenté,...) exprime un fait objectif (« il a deux jambes », « il a vingt ans »,...), le classement dans la voix descriptive se justifie complètement. Ce reclassement permet d’assurer une transition convenable entre les voix et les aires événementielles étant observé que :
- l’aire a englobe l’équatif et le descriptif statifs
- l’aire b correspond à l’équatif et au descriptif évolutif et à tous les causatifs
- l’aire g correspond au situatif
- l’aire m correspond au subjectif.
- enfin l’existentiel de la rosace des possibles s’identifie à la voix existentielle.
Il nous paraît que la voix s’intègre idéalement à la notion de domaine telle qu’elle est employée par F. Rastier dans la définition de la structure des sèmes génériques composant le classème d’un sémème. Seulement, nous sommes bien obligés d’admettre dans ce cas que le domaine se définit par au moins deux sèmes correspondant respectivement à la voix et au statut.
Pratiquement, quel usage envisageons-nous de faire de cette classification ?
La première application consistera à déterminer la voix de chaque énoncé.
Connaissant le sémème de chaque lexème, nous allons « calculer » le sémème de chaque groupe, puis de chaque syntagme. La combinaison des sémèmes du SV et du SN ou SA associés doit nous permettre de déterminer la voix. Ainsi, dans « avoir faim », l’auxiliaire avoir pouvant se trouver aussi bien en DES qu’en SUB, l’appartenance de « faim » à SUB permet de sélectionner la voix SUB.
Plutôt que de déterminer par avance les règles de calcul qui président à la sélection des sèmes, à leur activation ou à leur neutralisation, nous préférons procéder de façon empirique et traiter suffisamment d’exemples pour mesurer les difficultés rencontrées et déduire de l’analyse les régularités qui pourront ensuite être reproduites de façon systématique.
En second lieu, dans la représentation que nous allons donner de chaque énoncé sous forme de graphe conceptuel, au lieu d’utiliser comme support de la relation directement le verbe, ou le substantif, lorsque celui-ci désigne une relation et non une entité, ainsi que cela est généralement pratiqué, nous allons utiliser l’une des cinq voix valant classes sémantiques fondamentales de relation, dont le verbe ou le substantif constitueront une occurrence particulière entièrement définie par son sémème.
Sachant que chaque lexème dispose de son module casuel, cette manière de représenter les énoncés est la seule qui permette réellement, lors de la génération ou phase onomasiologique, de générer différentes variantes d’un même graphe ou schème conceptuel en relations mutuelles de paraphrase.
Ainsi l’énoncé : « l’éducation est la première priorité nationale » prendra la forme :

Il va de soi que la relation peut être caractérisée par d’autres traits :
- traits logiques : réflexivité, symétrie, transitivité. Nous espérons pouvoir exploiter ces caractéristiques. En effet, comme le souligne G. Sabah (1990, p. 90), « l’intelligence artificielle est principalement intéressée par une représentation de la phrase à partir de laquelle des raisonnements portant essentiellement sur le sens pourront être menés ». La caractérisation des relations portées par les verbes ou les substantifs représentatifs de relations, permettent de construire des raisonnements.
- le temps et l’aspect, catégories bien connues en syntaxe.

En base de données :

Mais ils permettent de représenter des énoncés complexes. Soit la suite du texte :
« Afin de lui permettre de développer sa personnalité, d’élever son niveau de formation initiale et continue, de s’insérer dans la vie sociale et professionnelle, d’exercer sa citoyenneté. »

En base de données :

En base de données :





- Détails
- Catégorie parente: La théorie des voix ou sémantique des relations
Enoncé simple et énoncé complexe - la question de la coordination
Nous posons ici la question de la légitimité de la distinction entre énoncé simple et énoncé complexe.
Si l'on reprend, en effet, la définition selon laquelle l'énoncé complexe est une séquence d'énoncés simples coordonnés, la question centrale est celle de la coordination.
Il nous paraît que la légitimité existe à la condition expresse qu'il soit possible de recomposer l'énoncé complexe à partir des énoncés simples. Or, nous avons vu que les énoncés simples ne peuvent être recomposés à partir des schèmes d'entendement élémentaires que si l'on garde trace des relations qui les unissent au sein du modèle actanciel. Autrement dit, ce qui fait l'unité de l'énoncé simple, c'est le modèle actanciel sous-jacent, que l'on retrouve dans le modèle syntaxique. Ce qui fait l'unité des énoncés complexes, ce sont les coordinations entre les énoncés simples qui les composent. Nous verrons que, contrairement à l’exemple étudié, il n’est pas toujours possible de recomposer les coordinations entre énoncés simples, le type de coordination ne pouvant se présumer sans une mémorisation préalable. C’est au niveau sémantique que les coordinations devront être traitées. Ce qui implique la nécessité de construire des modèles actanciels adaptés à la structure des énoncés complexes.
Cette constatation a une conséquence essentielle concernant le problème de la multiplicité des variantes possibles d'un même texte. En effet, il résulte de ce qui précède que les possibilités de variantes existent sans perte de sens significative à l'intérieur des énoncées simples, en agissant sur le modèle actanciel et notamment en faisant varier le niveau d'intégration des composants (cf. p. 195). Ces possibilités existent également à l'intérieur des énoncés complexes au niveau des coordinations.
Observons dès maintenant qu'au-delà de l'énoncé complexe, les coordinations existent au sein des énoncés simples et également entre énoncés complexes. Du fait de l'existence de ces coordinations entre énoncés complexes, moins explicites que les coordinations internes, il est clair qu'il existe une certaine porosité entre les énoncés complexes et le reste du texte avec lequel ils entretiennent des connexions logiques. Ce point, qui ouvre de nombreuses possibilités de variations sémantico-syntaxiques autour d'un même modèle conceptuel, serait à développer.
Les sémèmes permettent de raisonner
Une des utilités de l’analyse sémique est de permettre la génération automatique de taxinomies dans lesquelles les lexèmes sont ordonnés en hyperonymes et hyponymes.
Par définition, un hyperonyme possède un sémème qui est un sous-ensemble du sémème de son ou de ses hyponymes. Sémantiquement, l’hyponyme est lié à son hyperonyme par une relation « sorte de... », relation transitive.
L’analyse sémique permet de construire des raisonnements simples et de répondre à des questions sur un texte ou un domaine de connaissance pour lequel aura été constitué un dictionnaire sémique ou base de connaissances sémantique.
Si, par exemple, nous définissons une université comme étant un établissement public, nous pouvons en inférer qu’une université possède la personnalité morale du fait que :
- l’établissement public est une personne morale de droit public
- le fait d’être une personne morale entraîne que l’on possède la qualité de personne morale.
Ceci se déduit sans difficulté de l’analyse sémique.
La question étant « une université est-elle une personnalité morale ? », la réponse à cette question est subordonnée à la réalisation de trois conditions :
- si la base de connaissance sémantique a été construite de façon à contenir non seulement le sémème d’établissement public, mais aussi son ensemble de définition, dont nous donnons un aperçu ci-après, cette base de connaissance comporte toutes les informations permettant de répondre à la question ;
- il convient de disposer d’un algorithme de recherche adéquat
- le système doit être en mesure de comprendre le sens de la question ? Cet aspect est d'une grande importance, mais, bien que lié à notre recherche, il n’en constitue pas l’élément principal.

S’agissant de l’algorithme de recherche, pour arriver à faire le lien entre personne morale et université, le système doit d’abord rechercher dans le texte si celui-ci contient la réponse. À cet égard, l’analyse de la question montre que nous sommes au regard de la théorie des voix (cf. p. 276) en présence d’un équatif et donc nous pouvons poser sur la base de données un filtre qui ne sélectionne que les relations de type équatif. Ainsi, il est inutile de traiter une relation qui dirait que l’université est habilitée à délivrer des diplômes, qui est une relation de type descriptif. En cas d’échec, il convient d’interroger les taxinomies en partant soit de « personne » pour arriver à université, soit d’université pour arriver à « personne morale ».
Selon le premier cheminement, il faut d’abord naviguer dans la base de connaissance en parcourant tous les nœuds de l’arborescence de l’ensemble de définition contenant « personne morale » dans le sens descendant, jusqu’à trouver « université ».
L’autre cheminement possible est de partir d’« université », et d’interroger la base de connaissance sémantique et de parcourir l’arbre dans le sens ascendant jusqu’à trouver "personne morale".
Il est plus facile d’interroger la taxinomie à partir de « personne morale » qu’à partir d’« université » parce qu’« université » peut appartenir à plusieurs taxinomies. Par exemple, université peut appartenir aussi bien à la taxinomie qui détaille toutes les formes de personnalité juridique, qu’à la taxinomie qui classe les différents types d’établissements d’enseignement, non pas en raison de leur statut juridique, mais en raison de leur fonction pédagogique. Donc, il convient de conduire la recherche de préférence à partir de l’hyperonyme et non de l’hyponyme.
Donc, nous pensons que le fait d’identifier dans la question un certain type de relation est un élément de compréhension de la question essentielle pour conduire ensuite la recherche avec efficacité.
On notera toutefois que si la question est libellée « L’université a-t-elle la personnalité morale », il ne s’agit pas d’une relation équative, mais d’une relation descriptive de la seconde forme, et qu’il n’est pas possible de rattacher directement cette formulation à une relation du texte qui dirait « l’université est un établissement public ». Il faudrait que le texte dise « l’université a la qualité d’un établissement public » pour que l’algorithme que nous venons de décrire soit opératoire. Il est donc nécessaire dans cet exemple d’opérer sur le libellé initial de la question une transformation dans la voix équative. Et comme on ne sait jamais à l’avance la variante utilisée dans le texte, il sera toujours nécessaire, en cas d'échec de la première recherche, de reformuler la question.
Cet exemple peut être analysé autrement. L’expression « avoir la qualité de » peut être interprétée comme caractéristique d’un équatif et non d’un descriptif. Auquel cas, la reformulation qui doit être appliquée consiste à rechercher les synonymies au sein des relations caractéristiques d’une voix donnée. Dans notre exemple où nous avons le module « SN être SN », la synonymie (relative) entre « être » et « avoir la qualité de » dans ce contexte est facile à établir. Quoi qu’il en soit, pour que la recherche soit une recherche intelligente, il est nécessaire de prévoir d’opérer sur le texte même de la question différentes transformations en cas d’échec de la recherche directe. Et il est évident que le nombre de transformations possibles s'accroît avec la longueur de la question de manière exponentielle. Les transformations pourront porter sur différentes visions au sein du module, mais aussi sur la synonymie et les variantes paraphrastiques éventuelles. Il s’agit d’une combinatoire redoutable qui ne nous intéresse pas directement ici mais qui constitue une des difficultés majeures du traitement en langue naturelle ici envisagé.
Nous venons de voir un exemple dans lequel la recherche doit parcourir le taxème dans le sens ascendant ou dans le sens descendant et où la réponse dépend de la découverte sur ce parcours d’un terme existant dans le texte.
Mais nous pouvons imaginer que le terme de la question et le terme de la réponse se trouvent dans l’ensemble de définition, mais sur des branches différentes de cet ensemble. Imaginons que la question soit « l’université est-elle une association ? ». L’association est une personne morale, mais une personne morale de droit privé. La réponse pourrait être simplement « non, l’université n’est pas une association », ce qui traduirait l'échec de la recherche. Mais si le programme constate qu’« établissement public » fait partie du même ensemble de définition, mais qu’ils diffèrent au moins par les sèmes « public » et « privé », la réponse pourrait être « non, l’université est un établissement public ».
Il convient de souligner ici un aspect très important découlant de l’analyse sémique et de la notion d’ensemble de définition ou taxème. L’appartenance au même ensemble de définition permet de répondre « non, l’université est un établissement public », mais interdirait de répondre « non, l’université est une institution de formation », parce qu’« institution de formation » ne fait pas partie du même ensemble de définition qu’« association ».
On notera toutefois que la structure sémantique que l’on peut extraire de l’analyse des sémèmes fait apparaître des relations diverses qu’il convient d’identifier.
À la base, les éléments d’une même taxinomie sont unis par une relation « sorte de », « est un », « est une espèce de », etc., ce qui est le cas de « personne », qui en droit peut se décomposer en « personne physique » et « personne morale », « personne morale » pouvant se décomposer en « personne morale de droit public » et « personne morale de droit privé », etc. (voir schéma).
Toutefois, si l’on prend « personnalité », on ne pourra dire que « personnalité » appartient à la catégorie de « personne ». Selon des règles qui s’enseignent aujourd’hui à l’école primaire, « personnalité » s’obtient par dérivation de « personne » par l’ajout d’un suffixe porteur d’un sème « ité » qui veut dire « qui a la qualité de ».
Autrement dit, à partir d’un taxème donné, on devra construire un arbre comprenant non seulement les sous-catégories du lexème racine, mais aussi les différents lexèmes construits par dérivation ou par composition (« reconstruire qui s’obtient par composition à partir de « construire »).
Également, il convient d’inclure dans la même démarche les verbes ou les notions contraires, ceux que Gérard Sabah (opus cit. p. 95) appelle les verbes converses qui forment des couples tels que : vendre-acheter, apprendre-enseigner, construire-démolir, etc. Ces cas dont l’analyse peut être systématisée relèvent tous des modèles sémantiques fondamentaux évoqués plus haut.
Allons plus loin. Si le taxème comporte dans son sémème la notion d’un ensemble composé d’éléments, on devra en déduire de l’appartenance à cet ensemble un certain nombre de caractéristiques héritées de l’ensemble de niveau supérieur. Prenons par exemple le taxème « nation », la « nationalité » qui est une qualité attachée à « nation » se reporte sur chacun des éléments composants cette nation. Ainsi, un citoyen de la nation française possède la « nationalité française ». Il s'agit d'une forme d'héritage distincte de l'héritage découlant de la relation "sorte de …".
Il est bien évident que, compte tenu de ce qui vient d’être dit, les cas de synonymie, mais aussi de paraphrase, sont susceptibles d’être traités au travers de l’analyse sémique. Quand on lit « le service public de l’éducation contribue à l’égalité des chances », et si l’on pose la question « le service public favorise-t-il l’égalité des chances ? », la forte ressemblance au niveau du sémème entre « contribuer à » et « favoriser », doit conduire à une réponse intelligente, c’est-à-dire positive.
La question évidemment délicate à laquelle nous souhaitons pouvoir répondre est de savoir à partir de quel moment ou jusqu’à quel point on peut considérer que deux lexèmes sont synonymes ou quasi synonymes, les sèmes qui les distinguent éventuellement pouvant être négligés.
Nous nous plaçons ici dans une perspective uniquement sémasiologique orientée vers l’interprétation des questions posées et non dans une perspective onomasiologique orientée vers la production d’énoncés en relations mutuelles de paraphrase. La production d’énoncés obéit à une combinatoire rapidement incontrôlable. Cependant, nous ne voyons pas d’autres moyens de générer des énoncés voulant dire à peu près la même chose que de partir d’ensembles de sèmes tels que si je veux signifier « qui mange des végétaux », j’ai le choix entre « qui mange des végétaux » et « herbivore ». On doit en effet partir de ce que l’on veut dire pour, à la suite de différents choix sémantiques puis syntaxiques, produire l’énoncé final. Il s’agit ici d’une perspective qui sort du champ immédiat de notre recherche, mais il nous apparaît que seul l’analyse sémique permet de progresser dans cette direction.
Les précédentes remarques suggèrent l’idée que l’analyse sémique est susceptible de jouer un rôle de reconnaissance du sens, par analogie avec la notion de reconnaissance des formes. Des syntagmes, dont on a vu qu’ils pouvaient par l’effet des transferts de catégorie recouvrir des ensembles complexes, sont ainsi reconnaissables à leur sémème. Il faut par exemple que deux énoncés syntaxiquement différents comme « j’entends hurler le vent » et « j’entends le vent hurler » puissent être interprétés comme des énoncés proches sinon identiques, ne serait-ce que parce que l’inversion entre « hurler » et « le vent » induit une différence de pondération sémantiquement significative mais que l’on peut vouloir négliger pour éviter de les considérer comme des énoncés radicalement différents.
Une hypothèse qui pourrait être étudiée et qui dépasse également le champ de cette étude, serait d’utiliser l’analyse sémique à des fins d’indexation.
Dans une recherche bibliographique, au lieu de procéder par mots-clés, liés à toute une série de synonymes ou de mots apparentés, on devrait pouvoir produire le ou les sémèmes composant l’interrogation et rechercher dans le texte des sémèmes identiques ou voisins.
Cette démarche devrait être comparée aux recherches actuelles qui, voulant dépasser le stade quelque peu limité des mots-clés, et dans le but de mieux cibler les recherches, partent de relations syntaxiques incluses dans la question posée et recherche dans le texte indexé des relations similaires (cf. Annie Coret, Bruno Menon, Danièle Schibler, Christophe Terrasse, 1994 ; Anne-Marie Guimier-Sorbets, 1993).
On peut aussi se demander si les traits logiques qui caractérisent certaines relations, et à ce titre, ont a priori leur place parmi les sèmes, ne permettent pas de construire d’authentiques raisonnements.
Les exemples que nous avons utilisés jusqu’ici reposaient sur une relation logiquement transitive (à différencier de la transitivité au sens syntaxique ») dans la mesure où si l’on pose que si l’université est un établissement public et que si l’établissement public est une personne morale de droit public, on peut en déduire que l’université est une personne morale de droit public.
Des opérations logiques sont également possibles par utilisation d’autres traits logiques des relations.
Prenons par exemple la relation « être marié à ». Cette relation est symétrique parce que si Pierre est marié à Jeanne, Jeanne est mariée à Pierre. Mais la relation « être l’épouse de » est antisymétrique, sans qu’il y ait besoin de le démontrer. Mais dans la mesure où la relation « être l’épouse de » implique la relation « être marié à » ou « être le conjoint de », de la même manière qu’« épouse » a pour hyperonyme « conjoint » ou « marié », mais comporte en outre le sème « féminin », on peut en inférer que si Jeanne est mariée à Pierre et que comme Jeanne est une femme, alors Jeanne est l’épouse de Pierre. Ceci dans un contexte où l’on a le droit de poser comme règle de gestion que la polygamie n’étant pas admise, Jeanne est bien l’épouse de Pierre et non une épouse de Pierre. On voit dans cet exemple intervenir des règles implicites dans l’énonciation, mais nécessairement explicites dans tout traitement, tandis que la déduction que Jeanne est l’épouse de Pierre se déduit directement des sémèmes.
Le fait que la relation « être marié à » soit symétrique rend impossible la double affirmation « Jean est marié à Jeanne » et « Jeanne est marié à Paul ».
Le fait que la relation « être marié à » soit intransitive interdirait a fortiori de déduire de ces deux propositions que Jean est marié à Paul. (Brian Bowen et Pavel Kocura, 1993)
Dans tous les cas qui précèdent, nous avons fait appel aux taxinomies associées soit aux substantifs en relations mutuelles d’équivalence, soit aux relations elles-mêmes.
Mais l’utilisation des taxinomies n’est pas toujours possible. Si la question est « les universités sont-elles habilitées à délivrer les diplômes ? », aucune taxinomie qui reposerait sur une relation de base « sorte de... », ne peut contenir la réponse. La seule ressource est d’interroger l’ensemble des relations contenues dans le texte ayant pour base « université ». Nous utiliserons néanmoins un filtre, la question étant fondée sur une relation descriptive. Seules les relations descriptives devront donc être examinées.
Nous pensons donc que l’analyse sémique donne les moyens d’élaborer des raisonnements et nous regrettons de n’être pas en mesure de pousser plus loin dans cette voie car nous sortirions du champ plus restreint de notre recherche.
Toutefois, par un dernier exemple, il peut être utile de montrer les limites du traitement logique lui-même.
Dans une étude très profonde, déjà évoquée (cf.137), Paul Amselek (1992) dans le but d’illustrer les limites de la logique déontique, donne l’exemple de la règle suivante : « il est interdit de marcher sur les pelouses ». Si l’on considère que ce qui n’est pas interdit est autorisé, un traitement purement logique permettrait d’affirmer qu’il est autorisé de faire de la moto sur les pelouses.
Or, si les règlements dans les jardins publics ne posent que cette règle simple, c’est parce que précisément elle est simple, courte et directement compréhensible par nos concitoyens qui, devant cette interdiction, n’auraient pas l’idée, sauf par malveillance ou pour défier les règlements, de faire de la moto sur les pelouses.
En fait, il faut comprendre que cette réglementation a un but de protection de la pelouse qui est un objet fragile susceptible de détérioration. Alors que « marcher » sur un trottoir n’implique aucune idée de détérioration, « marcher sur une pelouse » peut impliquer une telle idée, sans que l’on puisse toujours l’affirmer, toute pelouse n’étant ni nécessairement fragile, ni nécessairement protégée. Mais si une pelouse fait ainsi l’objet d’une mesure de protection, toute activité plus néfaste que le simple fait de marcher sur la pelouse doit logiquement être également interdite sans qu’il soit nécessaire de l’écrire. Qui interdit le moins, interdit également le plus.
Autrement dit, si la logique déontique a tort, ce n’est pas parce que la logique est intrinsèquement incapable de résoudre un tel cas, mais parce que la règle logique que l’on voudrait y appliquer n’est pas la bonne. Dès lors, la question devient de savoir comment déterminer la bonne règle.
En fait, l’interdiction en droit est généralement associée à une idée de nuisance à autrui, de nuisance à un bien fragile et protégé ou de danger. Dans ces hypothèses, interdire le moins, implique que le plus est également interdit. La règle selon laquelle tout ce qui n’est pas interdit est autorisé demeure dans tous les cas où la règle précédente ne s’applique pas. La question devient de savoir comment déterminer le plus par rapport au moins. Comment faire, sémantiquement parlant, pour comprendre qu’il est au moins aussi nuisible pour la pelouse d’y faire de la moto que de la piétiner. Il est bien clair que l’analyse sémique en contexte nous donne la réponse, mais il faut convenir que cette analyse échappe à toute possibilité d’automatisation, à moins d’introduire dans le sémantème de moto le sème « détériore les sols fragiles », et dans le sémantème de « pelouse » le sème « sol fragile ». Dans ce cas, l’interpréteur devrait établir le lien et, appliquant la règle précédente, donner une réponse satisfaisante. Mais, il n’y a aucune raison de ne pas étendre cette démarche à tous les cas les plus farfelus qui pourraient se présenter. Ainsi, il ne devrait pas non plus être possible de faire du vélo sur les pelouses, de la patinette, de la voiture à pédales, voire d’y déposer des objets lourds et encombrants. Malgré la difficulté de prévoir toutes les situations possibles, notons toutefois que c’est précisément la difficulté à laquelle se trouve confrontée toute autorité investie d’un pouvoir de réglementation. Par ailleurs, le raisonnement que nous venons d’amorcer est précisément celui que tout juge est conduit à faire devant une situation de ce type : d’abord apprécier les faits (le caractère de nuisance ou non de l’acte ou de l’activité incriminée) et ensuite déterminer la règle applicable.
Justement, peut-on envisager de conférer à un programme intelligent une capacité d’appréciation des faits égale à celle d’un juge. On peut en douter.
Cette discussion nous paraissait utile bien qu’elle se situe aux marges de notre recherche aux objectifs beaucoup plus modestes.
- Détails
- Catégorie parente: La théorie des voix ou sémantique des relations
Nécessité d’une codification de l’écriture sémique
Si l’on souhaite procéder à des traitements automatisés sur des structures sémiques, il est indispensable de codifier cette écriture de façon à :
- distinguer les sèmes génériques et les sèmes spécifiques
- distinguer les différentes catégories de sèmes génériques
- intégrer des relations entre sèmes : relations logiques (et : &, ou inclusif : v, ou exclusif : w, négatif : Ø) ou relations non logiques (prédicats)
- intégrer des sèmes extensibles en sémèmes ou des sémèmes réductibles à des sèmes.
- pouvoir comparer les sémèmes entre eux par référence aux modèles sémantiques fondamentaux. Par exemple, comment comparer « construire » et « démolir » si ce n’est par un signe logique signifiant « contraire de » ou « non », soit le signe normalisé « Ø». Comment traduire le positionnement dans la sinusoïde (cf. TAL p. 42) « passion », « amour », « désintérêt », « indifférence », « antipathie », « répulsion », « haine », « indifférence », « sympathie », « affection », « amour », « passion ». Faut-il retenir une échelle dans l’intensité ou faut-il classer chaque lexème, sur la base du sème « intensité » les uns par rapport aux autres immédiatement supérieur ou inférieur. Quoi qu’il en soit, le traitement automatique postule ce type de notation. Autant de question auxquelles nous proposons d’apporter les réponses provisoires suivantes :
- les sèmes génériques seront écrits en majuscule
- les sèmes génériques sont classés dans l’ordre : dimension, domaine (s), taxème (s)
- les sèmes spécifiques seront écrits en minuscule
- les sèmes spécifiques sont classés par ordre alphabétique
- les sèmes afférents seront suivis d’une double parenthèse
- les sèmes associés à une notion de quantification comporteront un argument précédé de « : ».
Le modèle binaire discontinu ne comporte pas de quantification à proprement parler puisqu’il ne comporte qu’une alternative : « être » ou « ne pas être ». Dès lors qu’est déterminé le terme de référence, son contraire est défini par la négation, cette négation n’ayant une traduction au niveau du sémantème que dans le cas où le contraire est léxèmisé.
Le modèle binaire continu comporte une continuité sémantique d’intention (TAL p. 36). Dans le cas par exemple de l’axe de probabilité allant d’« exclu » à « certain » :

Chaque sémème se distingue des autres par son « intensité d’assertion » avec deux pôles extrêmes et deux positions intermédiaires. Le pôle « exclu », « impossible », devrait avoir une intensité 0, le pôle « certain », « nécessaire » une intensité ¥. Par souci de simplification, l’essentiel étant d’indiquer une différence et non une quantification exacte, nous proposons de retenir comme pôle extrême 0 et 1. Les termes médians se voyant affecté un indice qui pourrait être 0,25 pour « possible » et « contingent » et 0,75 pour probable.
On écrira donc :
« exclu » : PROBABILITE, intensité : 0
« possible : PROBABILITE, intensité : 0,25
Le modèle ternaire continu ne pose pas de problème de quantification, car il se définit par une troisième terme qui englobe les deux pôles extrêmes. Il semble concerner principalement le système de repérage spatio-temporel et comporte trois visions fondamentales : vision prospective (avant, à, dessous, devant, jusqu’à), vision rétrospective (après, de, dessus, derrière, depuis) et vision coïncidente (à la fois avant et après (pendant, en,), devant et derrière (entre, dans), au-dessous et au-dessus (sur).
Le modèle ternaire discontinu dans lequel le troisième est différent des deux autres ne comporte pas non plus de quantification : « ici », « là », « ailleurs »; « temporel », « spatial », « notionnel »,etc.
Le modèle cyclique par définition continu est dérivé par itération du modèle binaire continu :


Dans cette variante à polarisation à une période, répétable, il devient nécessaire d’indiquer une orientation :
Rapetisser : TAILLE, intensité : 0,5, orientation : négative
Grandir : TAILLE, intensité : 0,5, orientation : positive
Être grand : TAILLE, intensité : 1, orientation : neutre
Être petit : TAILLE, intensité : 0, orientation : neutre

Interdit : DEVOIR, intensité : 0, orientation : neutre
Toléré : DEVOIR, intensité : 0,1, orientation : positive
Autorisé : DEVOIR, intensité : 0,3, orientation : positive
Libre : DEVOIR, intensité : 0,5, orientation : positive
Conseillé : DEVOIR, intensité : 0,6, orientation : positive
Recommandé : DEVOIR, intensité : 0,9, orientation : positive
Obligatoire : DEVOIR, intensité : 1, orientation : neutre
Facultatif : DEVOIR, intensité : 0,6, orientation : négative
Permis : DEVOIR, intensité : 0,5, orientation : négative
Déconseillé : DEVOIR, intensité : 0,3, orientation : négative
Interdit : DEVOIR, intensité : 0, orientation : neutre

Dans le modèle cyclique à polarisation ordonnée (sans retour au même), dont la réalité offre une très grande variété d’exemple, il convient d’introduire un troisième paramètre : la phase dont le nombre est limité à 2.
Ignorer : SAVOIR, intensité : 0, orientation : neutre, phase : neutre
Apprendre : SAVOIR, intensité : 0,5, orientation : positive, phase : 1
Savoir : SAVOIR, intensité : 1, orientation : neutre, phase : neutre
Oublier : SAVOIR, intensité : 0,5, orientation : négative, phase : 2
Se souvenir, réapprendre : SAVOIR, intensité : 0,5, orientation : positive, phase : 2
- les noèmes n’ont pas à être identifiés, car ils ne se situent pas au niveau linguistique, mais métalinguistique.
- Détails
- Catégorie parente: La langue
 Démarche générative
Démarche générative
Les conditions de la génération
La génération du texte, n'a pas pour objectif de restituer à l'identique le texte initial. Cette restitution à l'identique n'est qu'une des possibilités théoriques de la génération.
Plusieurs conditions doivent être réunies.
Il faut d'abord disposer, suite à l'analyse sémique, de l'arbre thématique du texte étudié.
Il faut déterminer un point d'entrée dans cet arbre, différents points d'entrées pouvant conduire à plusieurs organisations possibles. En fait, il est possible de démontrer que les textes normatifs, contrairement aux textes littéraires ou journalistiques, ont un nombre limité d'organisations possibles.
Il faut également disposer du dictionnaire sémémique. Il a nécessairement été constitué pour construire l'arbre taxinomique. Le dictionnaire sémémique permet de déceler les synonymies éventuelles et de générer des variantes fondées sur ces dernières ou sur des périphrases[1].
Sur le plan méthodologique, il convient de s'entendre sur les entités à manipuler.
Les entités initiales nous semblent devoir être de deux ordres :
- d'une part des mots et lexies, que nous désignerons en tant que molécules sémémiques car composés d’un ou plusieurs sémèmes, dont les sèmes sont soit activés soit désactivés du fait de l’association.
- d'autre part des schèmes linguistiques élémentaires liés et sémantiquement spécifiés (diathèse, vision, topicalisation, focalisation, etc.).
Les entités finales, syntaxiquement correctes, sont des énoncés simples ou complexes.
Le cheminement pour aller du schème à l’énoncé doit être explicité.
À partir de schèmes élémentaires on peut construire directement des énoncés simples. Et à partir d’énoncés simples on peut construire d’autres énoncés simples ou des énoncés complexes. À partir d’un énoncé simple et d’un énoncé complexe on ne peut obtenir qu’un énoncé complexe.
Schèmes liés ® syntactèmes ® énoncés simples ® énoncés simples ou complexes
Mais on peut traiter au niveau sémantique les schèmes pour obtenir des schèmes intégrés puis des énoncés simples, à partir desquels on construira des énoncés simples ou complexes.
Schèmes liés ® schèmes intégrés ® syntactèmes ® énoncés simples ® énoncés simples ou complexes
Il faut revenir sur les définitions des énoncés simples et complexes données page 199.
Ce qui différencie l’énoncé simple de l’énoncé complexe, c’est l’unicité de la base d’une part, l’unicité du groupe verbal d’autre part. S’il y a au moins deux bases ou au moins deux groupes verbaux coordonnés, on est en présence d’un énoncé complexe.
Cette observation en appelle deux autres.
Il convient d’abord d’approfondir la notion de coordination.
Celle-ci est envisagée dans ses trois aspects (Pottier 1974 § 244) : égalité (ou), addition (et), soustraction (mais). Nous aurons à vérifier si ces trois aspects épuisent les possibilités de formalisation. Par exemple, l’addition peut connaître deux variantes selon que l’on doit rendre compte de deux types de comportement : séquentialité ou simultanéité.
En second lieu, il faut souligner que la coordination se manifeste pour tous les composants de l'énoncé :
Dans l'énoncé simple, le fonctème nominal peut comprendre, outre un groupe substantival obligatoire, un ou plusieurs fonctèmes adjectivaux facultatifs. Le fonctème adjectival peut comprendre, outre l'adjectif, un ou plusieurs fonctèmes nominaux. Le fonctème verbal apparaît seul ou accompagné d'un ou plusieurs fonctèmes nominaux. Il peut en outre être composé, outre d'un syntagme verbal, d’un ou plusieurs fonctèmes adjectivaux.
Ajoutons que la subordination (modèle syntaxique), correspondant à la mise en dépendance (modèle actanciel), est admise dans l'énoncé simple. Or, on peut avoir des subordinations en cascade. L'énoncé simple peut donc en définitive être relativement complexe.
Enfin, au-delà des coordinations explicites, on trouvera dans le texte des coordinations logiques implicites qui seront prises en compte dans le modèle conceptuel mais dont le rendu sous forme d’énoncés pourra s’avérer délicat.
Remarquons par ailleurs que la définition du schème intégré donnée par Pottier (1974 p. 330) comme ‘‘schème réunissant plusieurs schèmes d’entendement, et n’en conservant qu’un seul en actance, les autres se situant en dépendance (subordination) ’’, crée une limitation particulière à laquelle il nous paraît inévitable de déroger de façon à obtenir la séquence générative suivante :
Schèmes liés ® schèmes intégrés ® syntactèmes ® énoncés simples
® énoncés simples ou complexes
D’ailleurs B. Pottier admet la possibilité de cette extension, puisqu’à partir de deux schèmes Pierre/arriver (SE1) et Paul/arriver (SE2), il construit un SI par factorisation donnant comme résultat par exemple « Pierre et Paul sont arrivés ».
Mais l’on voit immédiatement que s’engager dans un élargissement de la définition du schème intégré conduit inéluctablement à proposer également un élargissement de la structure du syntactème en autorisant la coordination au niveau de la base et/ou du groupe verbal pour obtenir la séquence suivante :
Schèmes liés ® schèmes intégrés ® syntactèmes intégrés ® énoncés simples ou complexes
Dans ces conditions, la combinatoire qui sera à la base des différentes variantes possibles du texte recomposé sera appliquée au niveau sémantique de préférence au niveau syntaxique.
Dernière observation. On peut s’interroger sur la nécessité de partir du niveau des schèmes élémentaires, lorsque ceux-ci ont pour objet de "désintégrer" des complexes substantivaux, adjectivaux ou verbaux, constitués par adjectivation.
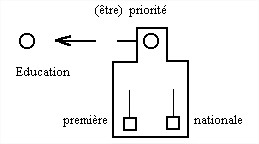
Ainsi, dans "L'éducation est la première priorité nationale." nous proposons de ne considérer que SI1 et non SE11, SE12 et SE13 (cf. page 192).
La question est plus délicate concernant la seconde phrase qui présente un cas remarquable de double factorisation.
La phrase "Le service public de l'éducation est conçu et organisé en fonction des élèves et des étudiants" est un énoncé complexe construit à partir de quatre énoncés simples imbriqués.
Pour reprendre les observations de B. Pottier (1974 p. 224), on peut se demander si l'on doit supposer quatre schèmes conceptuels de base, ou dire que le procédé d'intégration est mémorisé (=immédiatement conçu), et l'on aurait alors affaire à une syntaxie (ou modèle mémorisé), parallèle à la lexie.
Autrement dit, "conçu et organisé" et "élèves et étudiants" sont constitutifs de deux syntaxies qui renvoient à un schème intégré (SI2) (cf. p. 194), lequel renvoie à quatre schèmes d'entendement élémentaires SE21, SE22, SE23, SE24.
La question concrète qui est posée est de savoir s'il convient dans l'analyse relationnelle, dans l'optique de la génération, de descendre dans tous les cas au niveau des schèmes élémentaires.
Enfin, il faut également se poser la question de la reconnaissance automatique des schèmes élémentaires à intégrer, faute de quoi, il conviendrait de conserver au cours de l'analyse relationnelle la structure du schème intégré et la référence de ce schème intégré dans chaque schème élémentaire, auquel cas la décomposition du schème intégré en schèmes élémentaires ne se justifierait pas. En effet, le SI apparaîtrait comme une unité de signification dont les éléments constitutifs ne sauraient avoir d'existence indépendante sans perdre une partie de leurs propriétés.
Sans préjuger d'exemples plus complexes qui pourraient se présenter par la suite, il nous paraît que la recomposition du SI à partir des SE paraît envisageable mais au prix d'une combinatoire particulièrement complexe et aléatoire.
Nous ne considérerons donc pas, au moins provisoirement, les SE comme les unités élémentaires de signification manipulables dans le processus de génération, ce processus consistant dans la constitution et la reconstitution des phrases, puis de l'assemblage des phrases en paragraphes de différents niveaux.
Nous nous attacherons dans la suite à mettre en évidence des structures textuelles du niveau de l'énoncé simple ou complexe donnant le support nécessaire à l'analyse et à la génération.
Les structures de données nécessaires à la génération sont en définitive :
- le modèle global ou thématique ;
- les structures textuelles à définir
- les schèmes d'entendement formant un énoncé simple et attaché aux nœuds du modèle thématique ;
- le dictionnaire sémique que nous avons commencé à constituer, basé sur les molécules sémémiques à un ou plusieurs sémèmes ;
Les molécules sémémiques sont incluses dans les schèmes d'entendement, les schèmes d'entendement se rattachent aux nœuds du modèle thématique par la médiation des structures textuelles.
Application
Le modèle thématique ayant été donné précédemment, nous nous attacherons à la génération de phrases à partir des schèmes d'entendement.
Les étapes à suivre sont les suivantes :
Au premier nœud du modèle est attaché un seul schème d'entendement.
La base est par définition un complexe nominal. Le prédicat en l'occurrence est également constitué d'un complexe substantival.
Le syntactème est de type fN X fN’
À partir de la base et du prédicat, il s'agit de retrouver le fonctème nominal fN et le fonctème nominal fN'.
La structure du fonctème fN a été donnée plus haut.
La base ne comporte pas de relateur.
Le syntagme nominal SN, ne comporte pas de fonctèmes adjectivaux placés en dépendance.
Le déterminant est facultatif. Sans mention d'un quantificateur, il se limite à l'article dont il convient de déterminer le caractère indispensable ou non.
L'absence d'article se rencontre quand l'intention est de ne pas déterminer (Pottier 1974, p. 182).
Ici, la voix descriptive appliquée à 'éducation' est incompatible avec l'indétermination.
S'agissant du prédicat, la même démarche s'impose.
Le schème n'indique aucun relateur.
Le syntagme nominal comprend deux fonctèmes adjectivaux correspondants à deux schèmes élémentaires connectés au schème de base.
La présence d'au moins un fonctème adjectival exclut l'indétermination, donc impose l'article.
Il faut déterminer l'ordre des fonctèmes adjectivaux par rapport au fonctème nominal.
"première" est un adjectif numéral ordinal. Ce type d'adjectif s'emploie (Jean Dubois/René Lagane, 1989, p. 72) :
- avant un nom (mais après son déterminant quand celui-ci est exprimé)
- comme attribut
- comme substitut
Ici, sa place est avant le nom. On peut penser qu'il conviendrait de compléter, dans l'analyse sémique", la définition du taxème de "première" en précisant "supératif ordinal".
S'agissant de "nationale", il convient d'appliquer la règle générale qui veut que l'ordre "base+adjoint" donne à l'adjoint une valeur "objective" (dite souvent "sens propre"), tandis que l'ordre inverse "adjoint+base" correspond à une intégration sémantique où l'adjoint apparaît avec une valeur "subjective" (dite "sens figuré").
Ici, "nationale" a une valeur objective. On pourrait remplacer l'adjectif par "au plan national". S'il l'on ajoutait l'adjectif "vraie", avec une valeur subjective, on obtiendrait "la première vraie priorité nationale", formulation qui n'a pas réellement sa place dans un texte juridique, tandis que "la première priorité nationale vraie" n'aurait aucun sens dans la mesure où l'on ne voit pas ce que pourrait être une priorité objectivement vraie.
Nous pensons qu'il convient de considérer que par défaut tout adjoint (adjectif, adverbe) a une valeur objective. Ce principe se justifie particulièrement dès lors que l'on a affaire à un texte juridique.
À partir du SE, puis du syntactème correspondant, nous obtenons l’énoncé simple d’origine.
Il apparaît sur cet exemple simple qu'il est possible de parvenir à une génération qui respecte le sens original sans obstacle majeur.
Au second nœud du modèle sont attachés cinq schèmes d'entendement.
Les quatre premiers schèmes ont plusieurs points en commun.
- Leur base est vide (impersonnelle)
- Du point de vue de la vision :
- l'orientation est inverse, d'où la forme passive
- la visée porte sur le terme 3 : la lexie "service public de l'éducation"
INV 3 2 4 [1]
ou
INV 3 4 2 [1]
Le syntactème est de type fN X fA
La structure du fonctème fN a été donnée plus haut (page Erreur ! Signet non défini.).
La base ne comporte pas de relateur.
Le syntagme nominal SN, ne comporte pas de fonctèmes adjectivaux placés en dépendance.
Le déterminant est facultatif. Sans mention d'un quantificateur, il se limite à l'article dont il convient de déterminer le caractère indispensable ou non.
L'absence d'article se rencontre quand l'intention est de ne pas déterminer (Pottier 1974, p. 182).
Ici, la voix descriptive appliquée à 'service public de l'éducation' est incompatible avec l'indétermination. L'emploi de l'article défini est donc obligatoire.
S'agissant du prédicat, la même démarche s'impose.
Le prédicat est fondé sur un fonctème verbal de la forme fV2 (au moins deux actants).
Le schème indique le relateur : "en fonction de ", caractéristique d'une mise en dépendance notionnelle.
Le fonctème verbal est accompagné d'un fonctème nominal introduit par le relateur.
Le fonctème verbal ne comprend aucun fonctème adjectival.
Le fonctème nominal ne comprend non plus aucun fonctème adjectival.
Le fonctème nominal représente la généralité des élèves ou des étudiants et non d'élèves ou d'étudiants en particulier. C'est un trait qui doit être saisi au niveau de l'analyse sémique, et attaché au sémème ‘élève’ ou ‘étudiant’ en tant que sème afférent.
Dès lors, l'emploi de l'article "des", pour "de les" s'impose.
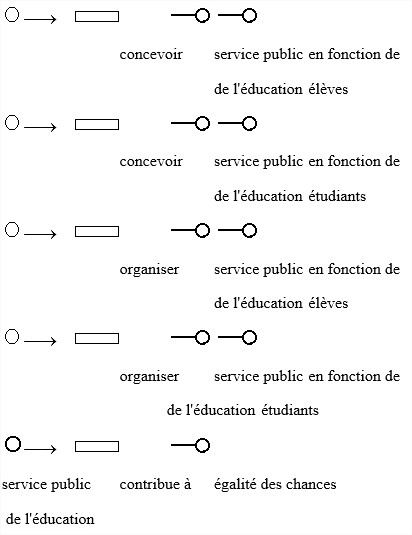
Nous obtenons ainsi les énoncés simples suivants :
"Le service public de l'éducation est conçu en fonction des élèves et des étudiants"
"Le service public de l'éducation est organisé en fonction des élèves et des étudiants"
« Le service public de l’éducation contribue à l’égalité des chances »
Les deux premiers énoncés se prêtent à une factorisation dont le schéma est le suivant :
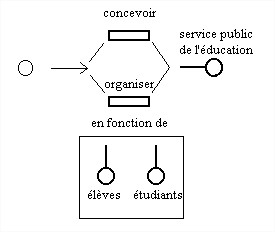
D'où l'énoncé complexe résultant suivant :
"Le service public de l'éducation est conçu et organisé en fonction des élèves et des étudiants".
Les possibilités de variantes sont les suivantes :
"Le service public de l'éducation est organisé et conçu en fonction des élèves et des étudiants ".
"Le service public de l'éducation en fonction des élèves et des étudiants est conçu et organisé".
"Le service public de l'éducation est conçu et organisé en fonction des étudiants et des élèves".
"Le service public de l'éducation en fonction des étudiants et des élèves est conçu et organisé ".
"Le service public de l'éducation en fonction des étudiants et des élèves est organisé et conçu ".
"Est conçu et organisé en fonction des élèves et des étudiants le service public de l'éducation".
"Est organisé et conçu en fonction des élèves et des étudiants le service public de l'éducation".
"Est conçu et organisé en fonction des étudiants et des élèves le service public de l'éducation".
"Est organisé et conçu en fonction des étudiants et des élèves le service public de l'éducation".
"En fonction des élèves et des étudiants est conçu et organisé le service public de l'éducation".
Le terme "organisé" ne peut pas précéder le terme "conçu". Il ne peut que le suivre. "Organiser" et "concevoir" ont l'un et l'autre un sème spécifique /prospectif/. Toutefois, sur l'axe de la chrono-expérience, l'organisation vient après la conception.
L'ordre de "élèves" et "étudiants" est indifférent, sauf à prendre en compte également la chrono-expérience qui veut que l'on soit élève avant d'être étudiant.
La place du fonctème nominal "en fonction des élèves et des étudiants" est normalement après le fonctème verbal. Le placer avant ou en début de phrase indique la recherche d'un effet littéraire qui n'a pas réellement sa place dans un texte normatif. Même remarque quand le fonctème verbal est placé en début ou en fin de phrase.
Le dernier schème d'entendement est rattaché au même nœud du modèle que les schèmes précédents. Ce nœud, « service public de l’éducation", est présentement la base réelle, alors qu’il n’était que la base apparente, imposée par la visée, dans les schèmes précédents. Sa place en fin de paragraphe ne s'impose pas en logique. Il pourrait tout aussi bien précéder l'énoncé précédent. On peut également le concevoir en dépendance par rapport à la base syntaxique de l’énoncé précédent, ce qui donnerait :
« Le service public de l’éducation, qui contribue à l’égalité des chances, est conçu et organisé en fonction des élèves et des étudiants. »
Cette mise en dépendance aurait pour effet d’affaiblir l’emphase mise sur la notion d’égalité des chances à travers un énoncé propre situé en fin de paragraphe. De plus, le lien logique avec le reste de l’énoncé n’est pas évident.
Cet exemple présente néanmoins un certain intérêt :
- il montre d’abord que l’énoncé, simple ou complexe, se prêtent à diverses manipulations ayant comme résultat un autre énoncé. Ainsi, avec deux énoncés simples, on peut faire un énoncé simple ou un énoncé complexe. Avec un énoncé simple et un énoncé complexe, on peut obtenir un énoncé complexe. Avec deux énoncés complexes, on ne peut engendrer qu’un énoncé complexe.
- il montre également que la phrase simple n’est pas l’unité minimale de sens. L’unité minimale est le morphème (Pottier 1974, p.327), indécomposable dans un état synchronique donné (Rastier 1989, p. 279), mais formant un système complexe à l’image d’un atome. Les mots sont construits à partir d’un ou plusieurs morphèmes. Les mots peuvent se regrouper dans des entités complexes mémorisées, les lexies. Les mots et lexies forment des molécules sémémiques et sont en relation les uns avec les autres au sein de structures élémentaires d’entendement, les schèmes d’entendement liés les uns aux autres au sein de schèmes intégrés, schèmes élémentaires et intégrés étant susceptibles d’être actualisés en langue sous forme d’énoncés simples. Les schèmes d’entendement sont capables de s’assembler selon des configurations variées, exprimées par les modules actanciels, pour former d’autres schèmes présentant divers paliers d’intégration, tous les schèmes d’entendement étant reliés les uns aux autres au sein du texte soit directement, soit par l’intermédiaire des divers nœuds du modèle thématique sous-jacent et dont nous avons amorcé la construction. Dans les mécanismes d'intégration et de coordination qui mènent des schèmes d'entendement au texte global, nous découvrirons des régularités, structures conceptuelles et textuelles propres aux textes normatifs, dont la mise en évidence permettra une rationalisation des processus d'analyse et de génération.
Mais avant d'atteindre ces structures conceptuelles et textuelles, quelques compléments concernant les mécanismes sémantiques de formation des énoncés sont tout à fait nécessaires.
Une classification rigoureuse des mécanismes de formation des énoncés
TAL (p. 112-116) apporte une analyse rigoureuse et achevée des mécanismes de transformation des énoncés en fonction de l’intention de l’énonciateur. Il s’agit en réalité d’une grammaire de production.
Le niveau linguistiquement le plus bas est le niveau conceptuel qui s’exprime par un schème conceptuel susceptible d’être illustré par une image, un film ou un dessin. Ce schème conceptuel est nommé par Pottier schème analytique (SA).
Le second niveau implique le choix par le locuteur des lexèmes, ce qui représente un premier niveau de contrainte sémantico-syntaxique. Il s’agit du passage de l’événement conceptualisé à son expression en langue naturelle. On obtient ainsi des schèmes d’entendement (SE).
Le locuteur doit ensuite choisir dans les lexèmes des schèmes d’entendement ceux qui composeront la base et ceux qui composeront le prédicat. Cette opération consiste à déterminer la vision du schème d’entendement. Le résultat de cette opération est un schème prédiqué (SP) qui permet de faire accéder le SE au statut d’énoncé.
En quatrième lieu, le locuteur peut appliquer au schème prédiqué une série d’opérations facultatives qui auront pour résultat un schème résultatif (SR) c’est-à-dire un schème complètement achevé du point de vue de l’intention du locuteur. Ces opérations sont notamment les suivantes :
- topicalisation : cette opération consiste à prendre comme topique un élément quelconque du SE, ce qui aboutit à créer une redondance dans l’énoncé relativement à cet élément qui est repris une fois en tant que tel, et une seconde fois sous forme d’un substitut, opération que Maurice Gross analyse comme un « détachement ». Ex. :
SP : les gendarmes ont arrêté les voleurs
SR : les gendarmes, ils ont arrêté les voleurs.
- focalisation : cette opération renforce l’emphase produite par la topicalisation : l’élément détaché est introduit par un présentateur. Ex. : Ce sont les gendarmes qui ont arrêté les voleurs.
- impersonnalisation : la tournure impersonnelle se traduit par la présence d’un présentateur tel que « il y a (que », « ça fait (que) ». Ex. : « il a été arrêté trois voleurs par les gendarmes ».
- réduction : cette opération consiste à omettre un élément du module. Ex. : « les voleurs ont été arrêtés »
- hiérarchisation : la hiérarchisation consiste à articuler entre eux les énoncés, qui peuvent être simplement juxtaposés (« Pierre traversa le pont. Il aperçut Jean »), coordonnés (« Pierre traversa le pont et aperçut Jean »), ou subordonnés (« Pierre traversait le pont lorsqu’il aperçut Jean »).
- Pottier n'a pas développé dans une présentation volontairement concise (opus cit., p. 120) la modalisation qui y a évidemment toute sa place, et dont on peut regretter l'absence dans le schéma présenté, d'autant que B. Pottier lui accorde par ailleurs une place fondamentale dans la structure de l'énoncé (1974, p. 158 à 188, TAL p. 210 à 224). Au demeurant, les opérations appliquées au SP se rattachent à la modalisation dans la mesure où elles manifestent une prise en charge de l'énoncé par le locuteur.
Parmi toutes les opérations facultatives qui viennent d’être rapidement passées en revue, nous considérons que les opérations de topicalisation et de focalisation n’appartiennent pas au langage du droit sauf preuve du contraire. En revanche, la tournure impersonnelle est d’usage courant (« il est créé un établissement... »). Le procédé de la réduction d’actance qui se traduit par la forme passive est aussi d’usage fréquent car il permet de ne pas mentionner un actant trop imprécis. La seconde phrase du premier alinéa de l’article 1 de la loi du 10 juillet 1989 en constitue un exemple parfait. Dans « le service public de l’éducation est conçu et organisé... », comme nous l’avons déjà noté, la réduction d’actance permet d’éviter la platitude consistant à choisir comme base une notion peu significative comme « les autorités compétentes », car l’on se doute bien que seules les autorités compétentes sont en mesure d’organiser le service public et il est inutile de donner à cette notion évidente et de peu d’intérêt un poids sémique important attaché à la position comme base de l’énoncé. Cette opération de réduction est complémentaire de l’opération de choix de la base qui est effectué au niveau de la production du schème prédiqué, et revient à gommer un élément qui n’a aucune importance ou sur lequel l’on n’estime pas nécessaire de retenir l’attention. En conséquence, lorsque nous rencontrerons cette situation, lors de l’analyse sémique, nous prendrons soin de considérer comme base de l’énoncé, celle du schème prédiqué et non celle du schème d’entendement.
Enfin, la hiérarchisation est une opération qui est complètement intégrée dans notre analyse syntaxique où notamment un énoncé qui pourrait être indépendant devient un complexe adjectival par transfert ou un élément marginal au regard du noyau de l’énoncé. On remarquera une similitude entre l’opération consistant à choisir la base du noyau de l’énoncé et celle consistant à choisir dans deux énoncés celui qui sera le noyau et celui qui sera l’élément marginal. Ainsi « Pierre traversait le pont lorsqu’il aperçut Jean » n’est pas sémantiquement identique à « Pierre aperçut Jean alors qu’il traversait le pont ». Dans le premier cas, l’énonciateur met l’accent sur la circonstance que Pierre traversait le pont, alors que dans le second il attire l’attention sur le fait que Pierre aperçut Jean. Mais si l’on dit « Pierre traversait le pont et aperçut Jean », la relation entre les deux composants de l’énoncé complexe est une relation de succession dans le temps sur laquelle l’énonciateur n’a pas prise au niveau de l’interprétation de l’évènement.
En tout état de cause, les trois procédés de hiérarchisation ont pour effet de renforcer la cohérence textuelle, et il conviendra d’en tenir compte.
Conclusion
Nous avons développé une approche linguistique générale dans laquelle, au passage, nous avons noté si le langage du droit utilisait ou non tel ou tel aspect de l’expression linguistique. Ainsi nous avons vu que le langage du droit, neutre par définition, évitait les formulations faisant usage de topicalisations et focalisations par exemple.
Cependant, nous pouvons évoquer la question de la spécificité du langage du droit autrement. Au lieu de considérer que le langage du droit fait un usage plus ou moins important de telle ou telle forme sémantique de base, on peut et on doit se poser la question de savoir s’il existe dans le langage du droit des structures qui lui sont spécifiques.
C’est ce que nous allons nous efforcer de voir dans notre troisième partie consacrée au langage et au droit.
[1] Nous ne développons pas ici les difficultés propres à ce type de démarche étudiée de manière approfondie par Catherine Fuchs (1994).